Having a really weird issue with the File: Open / File: Read functions in Venus 5.
I am using a worklist to build a sequence with the labware ID in one column, and position in another. However, I recently had a user’s run fail. For one column, it read in half the positions as blank strings and the rest as numbers.
Through trial and error, it seems like it’s only happening when half or more of the positions are in Row F. My assumption based on my trials is it’s seeing “F#” as a number. When it opens the file, it looks at the first handful of rows, sees that half are numbers and casts everything in that column as a number making anything that looks like “F#” into a number and everything else into a null value (even though I’m casting it as a string in the File: Read command). It seems like Venus is inferring the type on File: Open and then recasting when File: Read is run maybe?
Has anyone seen this behavior before and have a good workaround? The thing I know will work is really annoying because I would have to edit my method and the code that generates the worklist. I can enclose the position ID in single-quotes and do a StrReplace to remove the single quotes before adding the element to the sequence.
If you are worklisting with CSV or another type of structured text file, this is a limitation with some of the Microsoft Jet drivers VENUS needs to use to interact with various file types. For various reasons, these drivers can be tempermental when reading files that contain alphanumeric strings (mixed types).
For starters, if the filepath of the worklist is being reused from run to run, you will want to be sure to delete the automatically generated ‘schema.ini’ file used by the Jet drivers to inform how to process each column of data (including mixed types).
Check this post for more context:
Additionally, in this instance, it often helps to open in ‘Append’ mode instead of ‘Read’ mode. This results in more robust processing of mixed strings.
Thanks Nick,
That’s a good tip about the Schema file. I don’t think that was an effect in this case because each worklist is unique to the experiment being run and has a unique name. Good to know regardless because there are other methods we use constant worklists for.
Re: opening in append mode, I’ll give that a shot. Hopefully that will help me avoid the nuclear option. Thank you!
Thanks @NickHealy_Hamilton for your suggestions. By coincidence I’ve just had a very similar issue with a worklist and alphanumeric positions containing F#. Changing the file open to append seems to have fixed the issue.
That’s interesting that you had a similar problem Harrison, I figured my use case was somewhat unique because I’m running a serial dilution on a plate in portrait orientation.
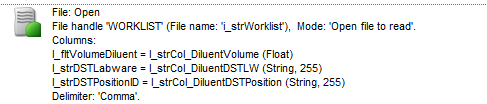
Opening in Append mode didn’t actually work for me, but I think I know why. When I open the file, I’m using variables to specify the columns that I’m intending to read (image below). However, when I opened in “Append” mode it only read the first 3 columns of the worklist and didn’t use the column headers I specified. It seems like this might have worked if I was reading in every column of the worklist in the exact order they are in the worklist (which I’m not because I have 60+ columns in this worklist)
Deleting the schema file didn’t work for me either.
In the end, I edited the code that generates my worklists to add an apostrophe to the end of the PositionID in every PositionID column. In my method, I used the StrReplace function from the HSLStrLib to remove the apostrophe after its read in.
In my case I am looking to perform a dilution in a 12 column reservoir and the labware is set up to have artificial ‘wells’ in each column to get all 8 tips used at once. The columns are labelled by letter and the ‘wells’ by number down the column and I was finding that it would error on position F8 declaring it invalid.
I am reading in a worklist and then appending values from this to a sequence for pipetting but my worklist is only 5 columns and I am accessing all of them. Perhaps this made the difference for me.