This has been blowing up, so much so that my non-industry friends have sent it to me:
There’s videos and other PR, but the paper has the most info. People are freaking out thinking chatGPT is running the arms ![]() will be fun for convos at SLAS
will be fun for convos at SLAS ![]()
This has been blowing up, so much so that my non-industry friends have sent it to me:
There’s videos and other PR, but the paper has the most info. People are freaking out thinking chatGPT is running the arms ![]() will be fun for convos at SLAS
will be fun for convos at SLAS ![]()
Interesting, what’s your take?
Also check out our hackathons in San Francisco! Link
We had one team benchmark every major LLM which I haven’t seen replicated at all yet.
Why use 1 when you can use all?
My rough thoughts are is….cool? But any well built automation platform should in theory be able to do this, it’s just a work list made from ChatGPT. As for the experimentation I’ll need to dive into it a bit. I’ve seen a ton of bad takes on twitter assuming the robots are fully driven from chatGPT.
The Pydantic layer is nice ngl. I don’t have the time for Twitter so feel free to share the worst ones.
I feel like the fundamentally enabling factor here is that they built a platform that can search a very large parameter space in a highly automated way, and that the software abstractions allow for experimental feedback that an AI can interpret. Presumably theres a lot of hardware choices that make this scale nicely. Definitely a great day to be working in this field.
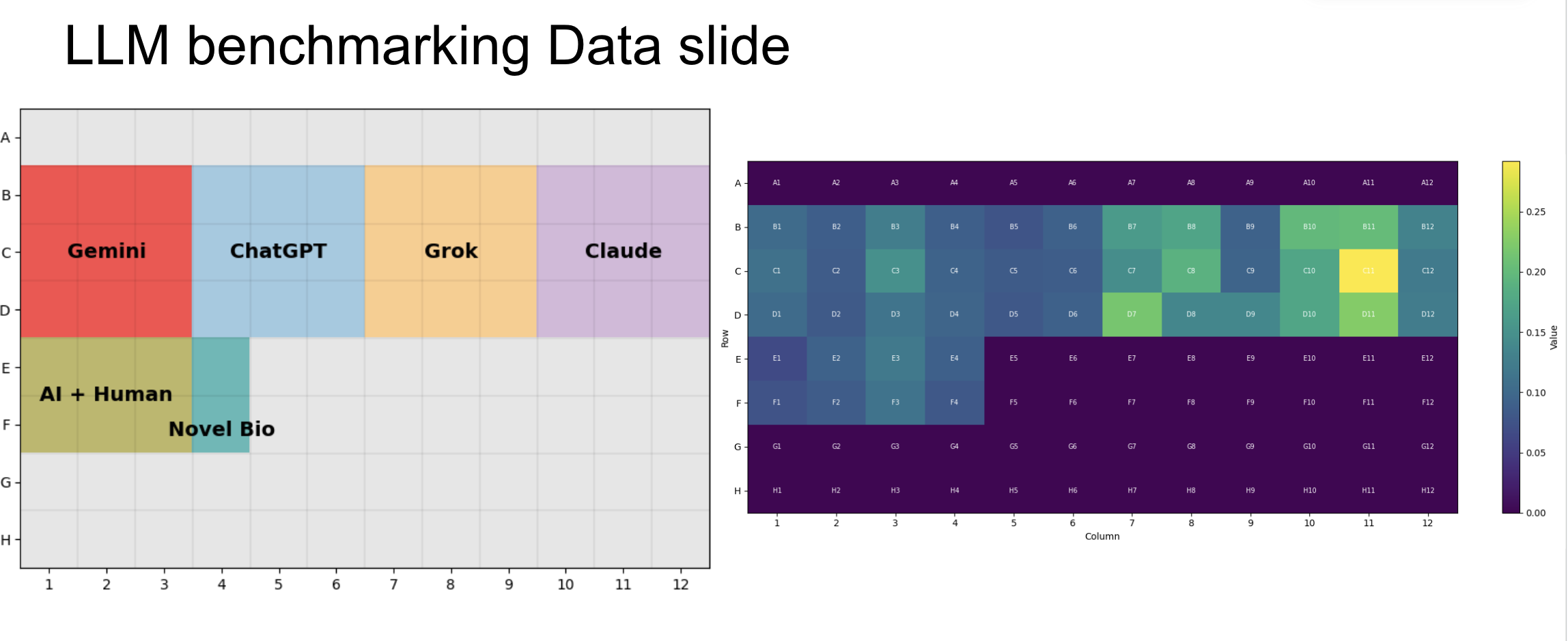
Wait is this a plate reader output where different parts of the plate were allocated to different LLMs lmao that is so good
Yep I was losing my mind when I saw this slide, same prompt for all models.
The AI provided the recipes and then AI automated the execution.
It’s such a great slide.
Interesting work by Ginkgo, I especially like the pydantic validation to prune away the unrealistic or impractical reactions.
Scientifically however, I do think there are is a critical experiment missing to solidify the paper’s claim. The authors claim that the performance jump after step 3 was consistent with significant model performance gains seen by giving the LLM access to additional analysis tools and access to the internet. However, they clearly state that they changed both the DNA template as well as the recipe of the cell lysate after step 2 based on human reasoning rather than LLM recommendations. They would need to compare the LLM recipes generated during step 3 with the old reagents vs the new reagents to assess the impact of its reasoning in step 3.
While the authors never claimed there were no humans in the loop, they would need to show the relative contribution of the LLM recipe optimization vs the human contributions to the 40% and 27% reductions in the respective specific cost and production titer relative to the SOTA.