Has anyone been able to make a Fluent script for a simple normalization just using a .csv input with concentrations of the sample wells? The baked in commands in Fluent control seem to require Magellan output to get the starting concentrations, or go through sample tracking which seems to be more work than we really need.
fortuitously, i was just working on the same problem where the data captured by quant on a tecan system isn’t available (or difficult to access) for pipetting,
i’ve written .vb applications to handle this
i also used logic through FluentControl to write a volume file/volume files to execute using the “Transfer Individual volume” commands - this was the cleanest way & more efficient for tip consumption
Thanks, yeah I think I’m going to have to go an external route for now to get the dilution calculations done.
I’m just going to throw it out there but have you come across Synthace.
I run normalisation protocols on the Fluent literally everyday and I use Synthace to do this for me.
1 Like
Yes have used Synthace and do like it a lot, but it’s probably going to be overkill for what we want on this system. Though we are thinking of bringing it on eventually to do some DOE
1 Like
Today we tried to use worklist commands to transfer samples and diluents. it worked for samples, but not diluent for some reason. I was wondering if we could use “transfer individual volume” command and saw this. This forum is so great!
1 Like
TELL YOUR FRIENDS.
1 Like
There have been a couple of updates in beyond FC 3.1 but there is a Normalization calculator that can be linked to TIV as well as normalization from Megellan data.


Let me know if you need the manual but it is normally supplied with the install files.
1 Like
@MortenSkovsted thanks for the email. I had a quick look at if I had an example of how you can quickly implement an 8 loop import structure as this is normally how I have done this on EVOs. You can still look into how to use the other commands to simplify and error handle.
Disclaimer I have posted as roughed out solution here so everyone can see and discuss this. Note I have done this super quick so the Maths might not work and there is no error handling below.
This example is pulling data from a very basic csv file with one column of concentration (mg/ml) in order of well references. The process reads the first 8 lines/conc of the file calculates and assigns the calculated sample volume to each tip as and array.
This calculation is based on predefined values of Final Volume (FinalVol) you require and Final concentration you need (Conc). I have assumed its a 96 well plate.
There a couple of internal variables you may not be familiar with. I have first declared a file location/path as a variable “File” and use fileLineCount to give me the number of “Lines”/concentrations in the file. I will need this later to define the number of import cycles.
I have “Line” variable I will use a as count later to read a new line on each loop.
“NormConc” is the user defined value they want all samples to be normalized to and “FinalVol” is the total volume you want your finale sample to be. Note these can be user prompts but you will need to work out error handling for when Maths fails and tip accurate is limited. This is something the wizard like single commands in my last comment can do for you or you and if-else this yourself.
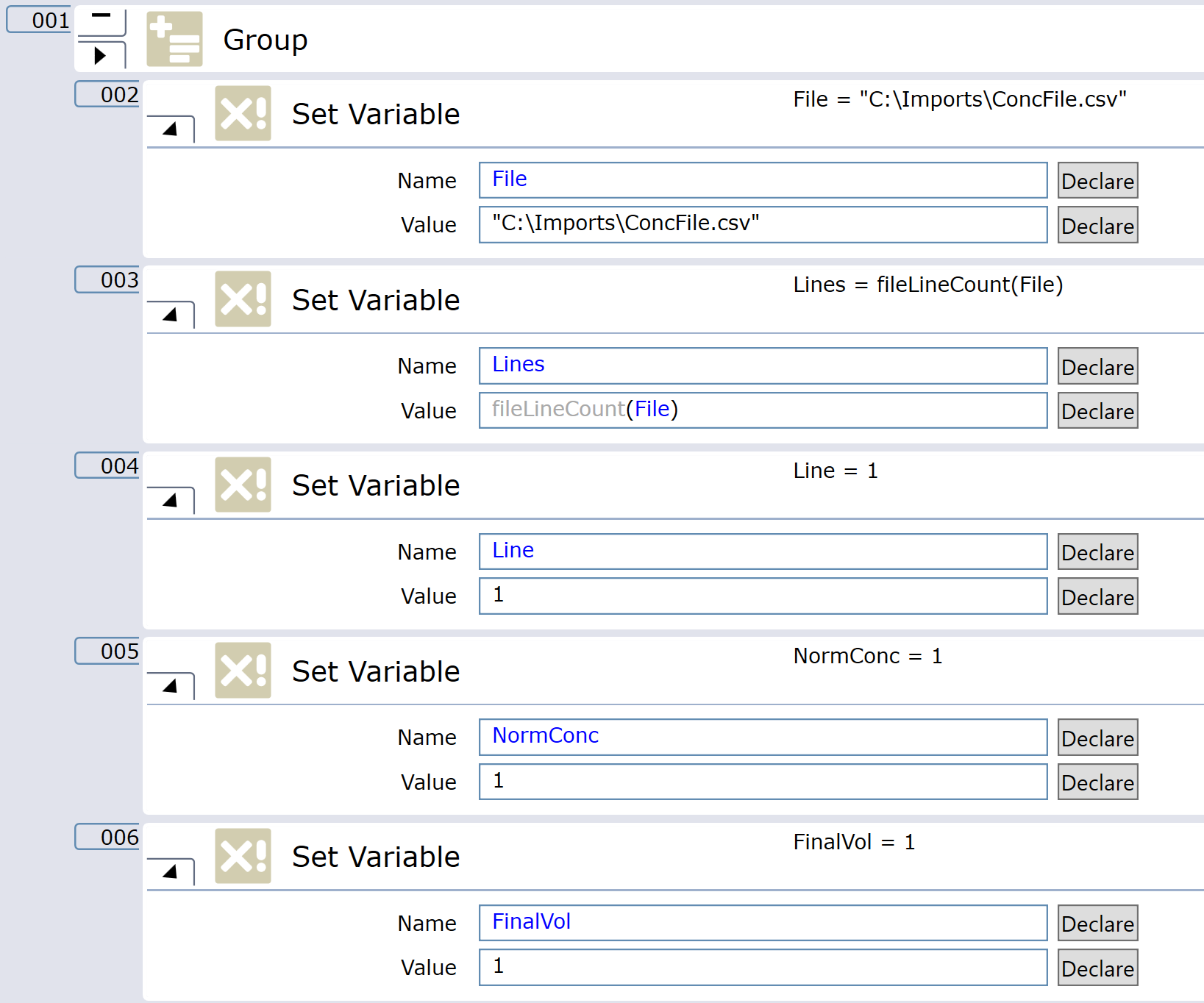
The next part is the looped import and calculations. First loop should be to support running until there is no more data in the file based on line counted. The nested 8 loop in is an import and assign volumes to the tip array. As each loop progresses I have include a Line+1 to make sure you import the next line of the file before it is assigned to the tip array.
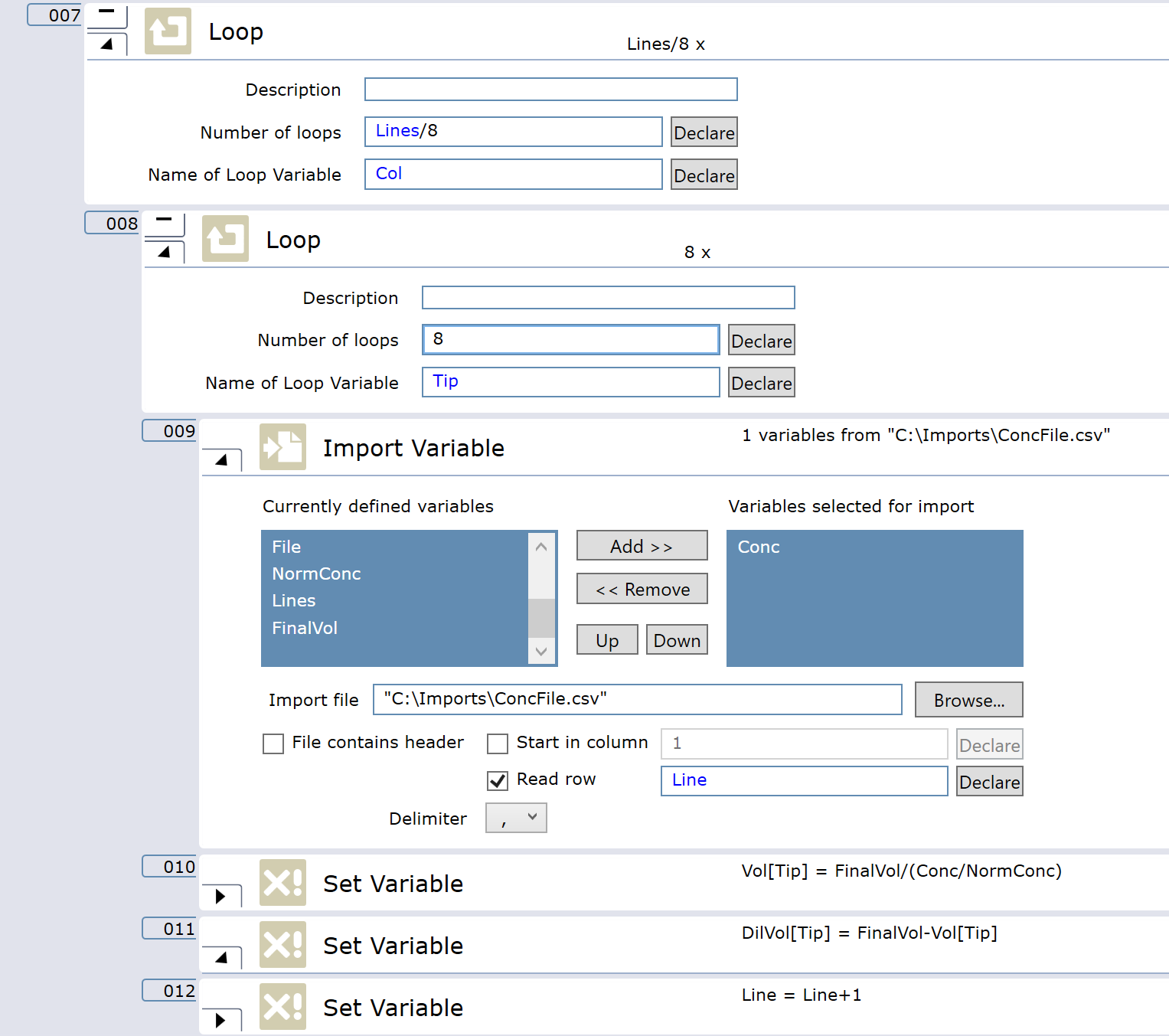
I have directly nested the pipetting commands into the first loop so each volume can be assign to the calculated volumes for the dilutant and sample to dispense in one go (plus 10% to clear the tips). Maybe you want to be more careful and split this out to dilutant and sample separate tips but EVOs and Fluent create air gaps and minimally touch liquids so this is the fastest way to normalize samples with low %CV.
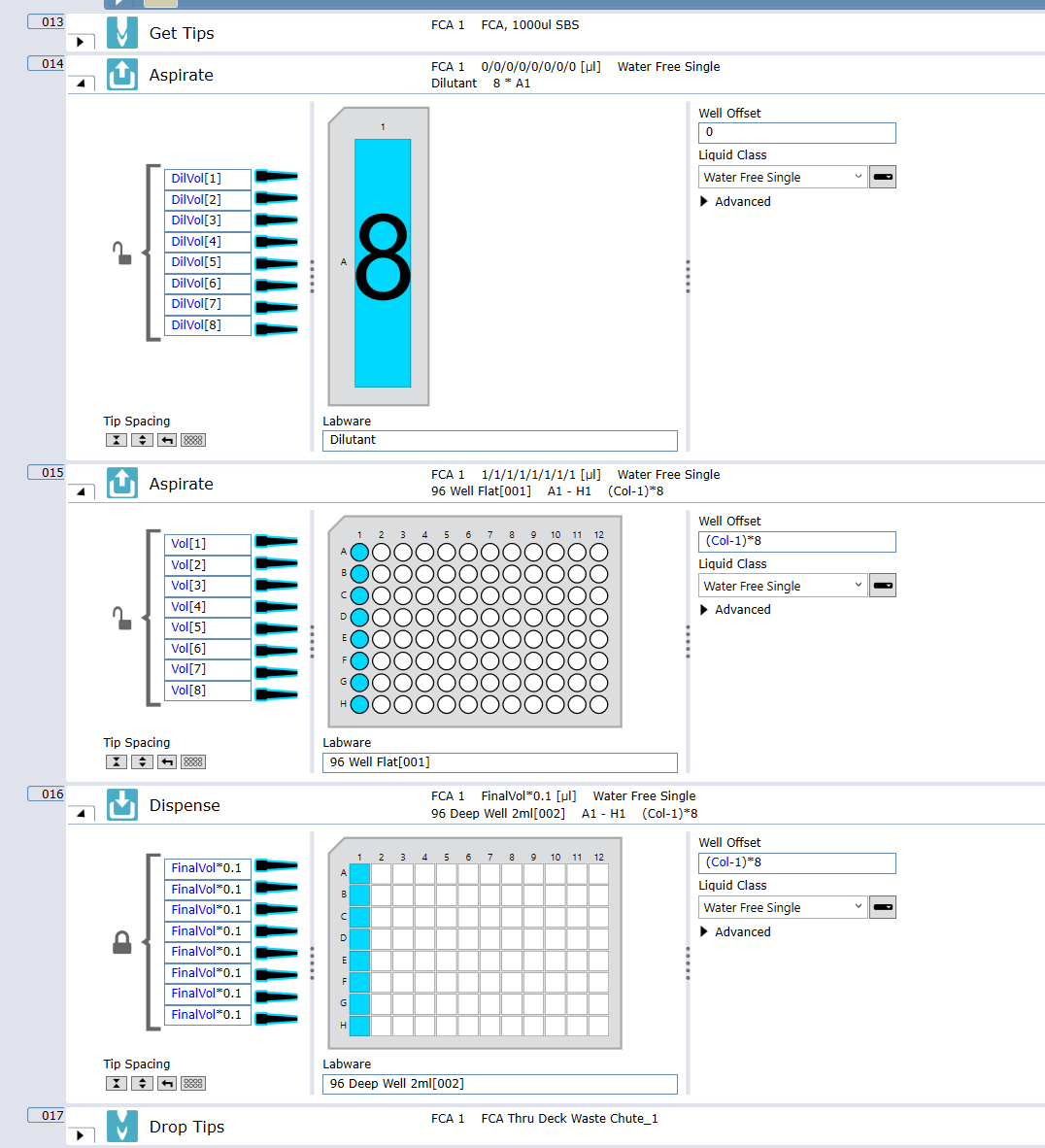
This still need a bit of work but gives you the basic idea and tools.
Let the Tecan team know if you need more general guidance. Enjoy!
3 Likes
@DanielYip, thanks for suggesting this idea!
Is Synthace compatible with the Infinite 200 PRO plate reader or something like a Lunatic if ran on the Tecan Fluent?
Hi Freddie, yes it is compatible, we can explore the use case in detail if you like?