Here’s a post I made about AI in lab automation, I was thinking a lot about this because of the panel talk I gave at SLAS and the recent discussion on here. I hope people aren’t getting tired of the topic but I find it very interesting and it will take a lot of care to navigate using these new tools productively. This forum is a great place to have these conversations.
I think the main point I want to convey to the forum is that using AI to write wholesale production scripts that work perfectly out of the box is not a great use-case, and that there are many very useful ways to use AI besides that. My day-to-day job is very similar to a typical automation engineer but the infrastructure I’ve built up in my lab for doing that job is very different. It’s taken me a while to build up a good set of practices so I’d love to try conveying those to the community.
A very valuable and growing area in our field is coupling data to execution, which takes a lot of different forms. The processes our robots run are often tied to a much larger data infrastructure that provides information about sample quantity, type, and so on. I’ve found it very helpful to build simulated testing infrastructure that represents the entire stack of how data flows to the robot methods and back. An agentic tool like Claude Code or Codex can run entire in-silico tests and catch errors throughout the pipeline, and then patch those errors itself with minimal human intervention. None of this takes the design control out of the hands of live engineers where it still belongs, but it’s enormously helpful at managing the complexity of data responsive pipelines.
I agree there are many productive ways to use AI today that aren’t protocol authoring but the ROI for CRO’s & CDMO’s & Foundries & Cloud Labs is extremely high. Academic labs and in-house automation solutions probably see a slightly different set of applications for AI and that’s what makes this so exciting.
Great stuff. I generally agree with most of your points about getting stuff up off the ground being easier than it’s ever been. My only real objection is that scaling an AI-built stack sounds like a nightmare. It’s a cliche, but writing code is easier than reading it, so I think the gap between “working prototype” and “production ready codebase” is a tad understated. Still, I agree that folks should give it a whirl, even if it’s just to see how close they get.
Also, thought this was interesting:
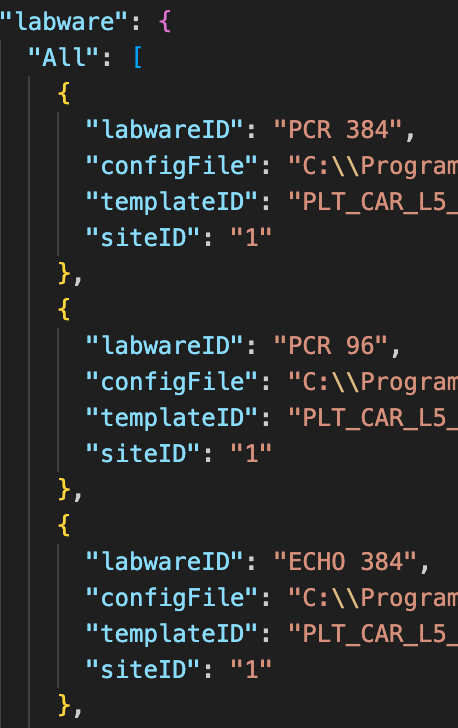
We don’t have to reinvent the wheel or all agree on one standard, but proprietary byte-encoded formats are used for a lot of files that would be far better off encoded in JSON. For example, Hamilton’s deck layout files implicitly describe the spatial positioning and geometry of all of the objects on the robot deck during a protocol with a very high resolution, yet this data is not natively accessible by any other program besides Hamilton’s own proprietary software. Converting these formats to something like JSON would not exactly be trivial, but is still ultimately just a matter of representing information that we already have about the system in a better way.
I feel so seen. This is actually how I’ve been doing it for years:
Tons of flexibility to to load decks dynamically based on the serial number or specific protocol requirements. We’ve debated extending the functionality for deck loading further, but there hasn’t really been a need.
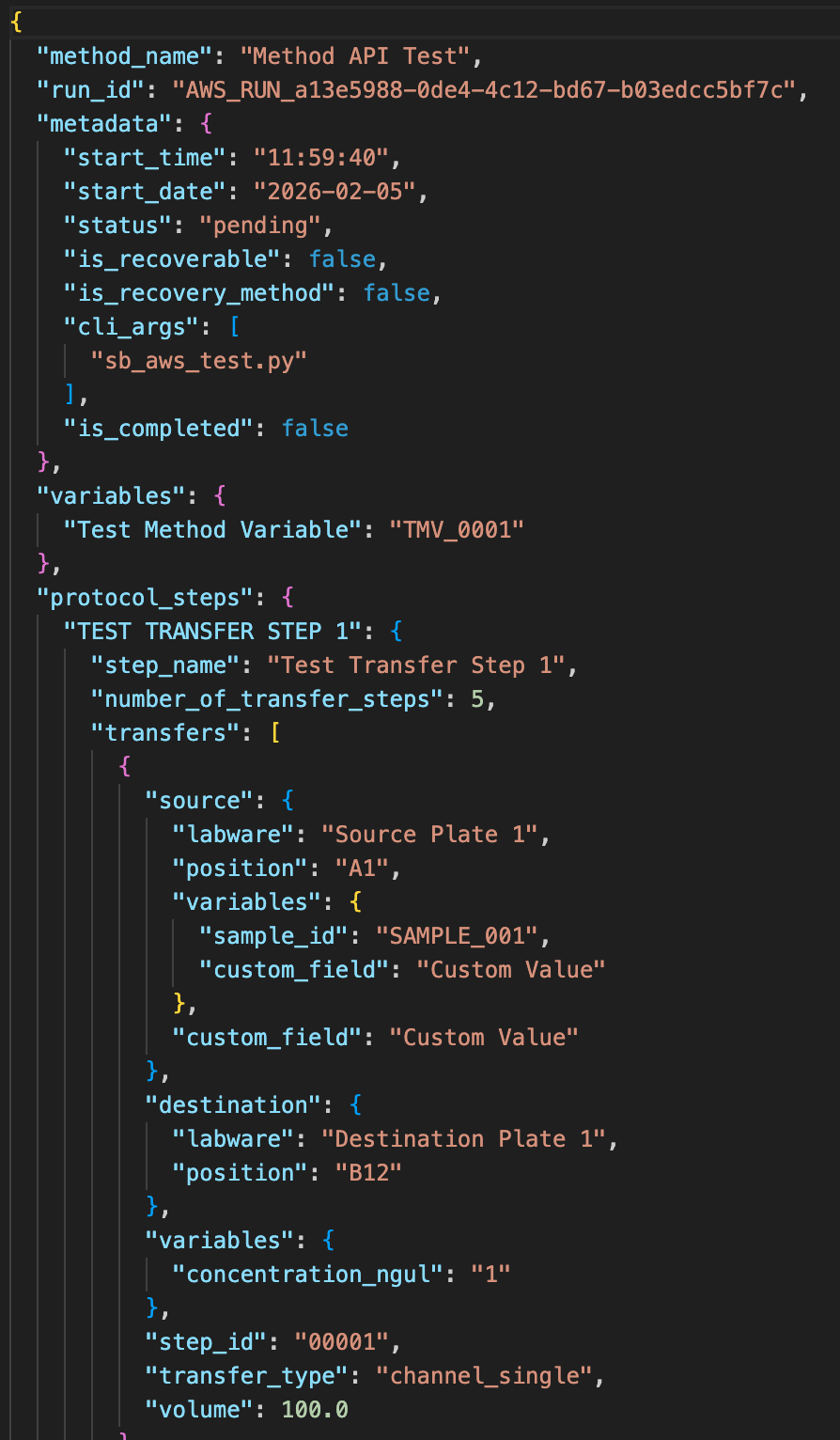
I’ve mentioned this elsewhere on the forum, but this strategy also works for building liquid handling transfer sequences as well, I’ve got a python package (that I’d love to open-source eventually) for writing scripts to generate transfer steps in JSON:
Hamilton has a library for importing json, so getting the data to the liquid handler is straightforward (if a little tedious), and because the scripts that generate these files are python based, they’re already close to plug-and-play with any AI coding tool out there once you include some instructions for the LLM
If AI can run simulations and catch errors, I wonder if it can also identify areas where the automation can be further optimized. In my experience a lot of contemporary automation is focused around emulating an existing manual workflow including the linear order manual processes occur. Using simulations or a gaant chart I wonder if AI can figure out ways to identify and utilize “dead time” to reduce total sample processing times.
i.e. Suggesting a reagent mix used a few steps ahead can be prepared while the sample plate is incubating on a magnet .
Above all, better digital integration and accessibility is the single biggest and most achievable unlock needed to leverage AI in lab automation. Standardized and machine readable file types will allow us to better model our systems in software, which directly assists in the creation of simulation and testing infrastructure.
Really liked this part! I agree that standardization (filetype and formatting) is critical to creating a robust multi-instrument AI framework.