For my aspiration I use the workflow with customized errorhandling for each step. This means that I read the stepreturn and decide - based upon the MainError - what to do.
Everything is working in a happy path, but in a unhappy path I am a bit puzzled how to operate with the hardware error.
For example
Operator loads reagents but forgets to put reagents in the tube. This results for a reagents to a “hardware error” (02/54) and the recovery right now is to inform the user and to reload reagents. However, right after the recovery I get into the “Plunger is outside of permitted area”
My guess is that I need to perform a tip eject and a new tip pickup correct? That way I can reset the plunger inside. Or is there any other way to accomplish this?
Could you share a trace file? It appears the original error you were getting was the “Plunger is outside of permitted area”. So, repeat was throwing the same error. Trace file will confirm.
Typically, you get this error if there is a Z stall mid aspiration that was repeated without dispensing back to the source or resetting the channel in some way.
The recovery for this is that the aspiration SMT returns a false to the main method, this in it turn keeps it in the 1:1 loop I have for each reagent aspiration. The next aspiration is going to retry (that would be the idea anyway)
The subsequent error is :
P1: Plunger drive, Position out of permitted area.]) (0x28 - 0x1 - 0x80a)
What my spidy sense told me is indeed that I need to perform a reset in a way of the plunger and to my knowledge this can be done at two ways, either dispense or perform a tip eject. Although I am not a 100% entirely sure this last one is correct.
Would it be sufficient then to check in the stepreturn errors for the main error (hardware / 02) and screen for the plungerdrive error (slave / 54)
Checking the firmware reference shows me there are a few errors that could happen, but the scenario I am currently investigating (a user ignored instructions and put an empty tube on deck) the situation would be only hardware error, because the Z-steploss might be triggered rather than cLLD error.
the original reason we had the hardware error was basically a wrong teaching of the labware. We noticed that the position was off by 10mm (basically a grand canyon could fit here). So we corrected this
after triggering an error, the system goes into “Errorhandling by the user” and the SRV is being processed. All channels with an hardware error are flagged and stored in an array the size of the SRV. At the end of errorhandling these channels are joined to a channelpattern by the HSLExtentions library STRING and then those affected channels are ejected to the waste and new tips picked-up.
This workflow works great and resolves my issue 100%
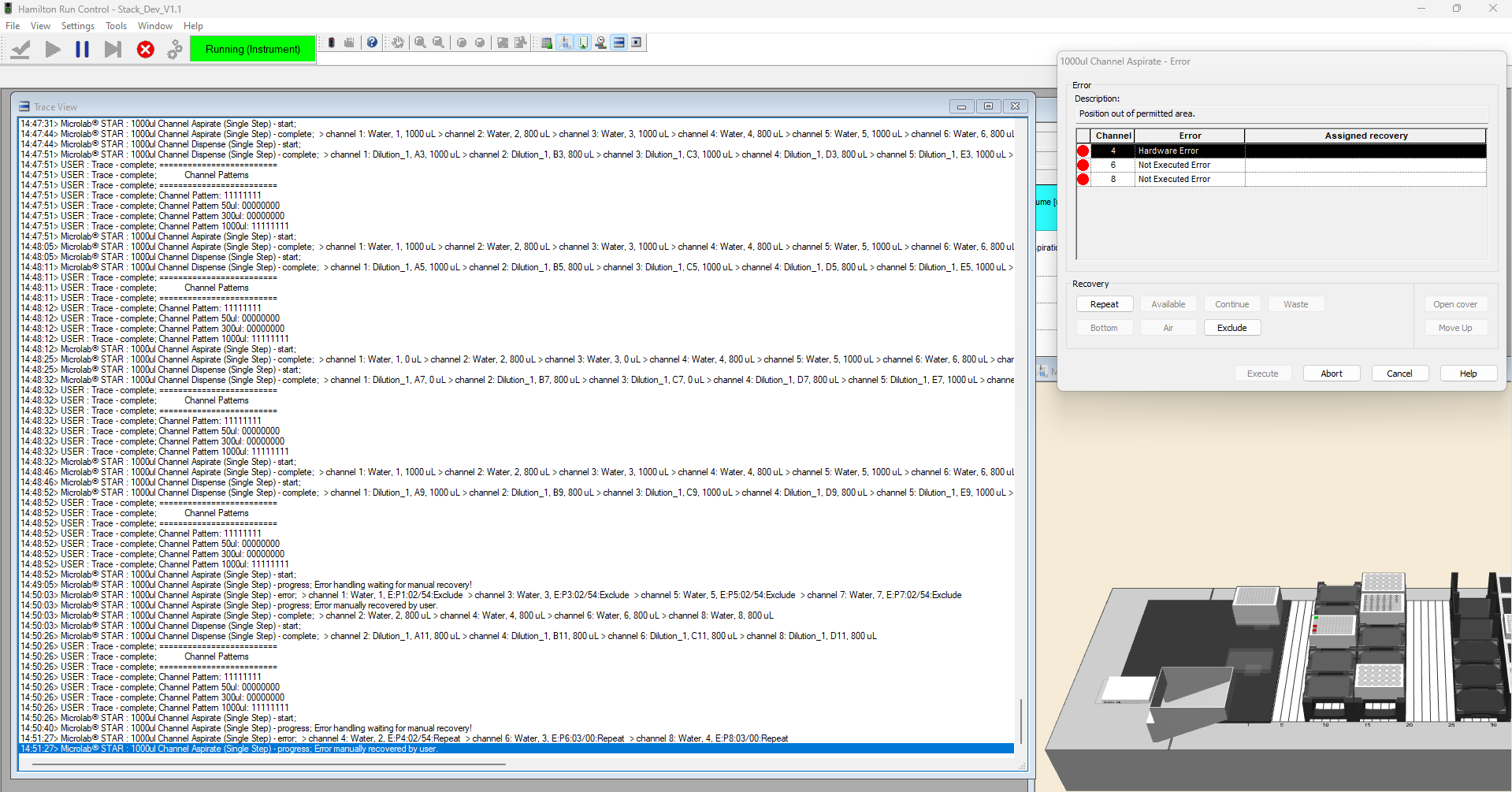
Following up on this thread because I’m getting a similar error. The error is “Position out of permitted area” as a hardware error. It occurs when dispensing reagent (water) multiple times using the same tip. Usually will pop up around the 3rd or 4th time trying to aspirate from a full trough of water that it has already been pipetting from, same seq positions even. I’ve gotten this issue across all cLLD settings (Low to Very High). The channel does not attempt to approach the trough. If you exclude the error will eventually persist across all channels. Seems like residual volume in the tip building up enough to throw off the cLLD.
I managed to get around it with pLLD but also just curious if anyone else has seen this error and what might be the cause.
See attached image for screenshot of error and trace.
It’s a bit hard telling what the exact reason for this could be. It could be as simple as your trough is running out of liquid and you are touching the bottom with only one channel or it could be teaching of the labware.
What is does sound like is as if you have not performed a full dispense or the plunger of the channel is not fully back to the original position. It’s then a accumulating effect. Aspiration 1 works, 2 still, 3 works but at 4 your plunger is at a hardware stop. Therefore I would check your aspiration step and dispense step. Make sure to have this properly. If you leave X uL in the tip for a reason, make sure to dispense it prior to an aspirate (you might do this with some aspiration/dispenses)
Thanks for the response! It’s dispensing the same volume that it aspirates and the trough still has a good amount of liquid in it (+100 mLs). Seems like someone else had this issue recently as well and posted about it here.
I think it has something to do with the plunger position as you suggested because of the disappearance of the error when swapping to pLLD. Maybe there is some positional drift going on, and because I’m transferring 1000ul the plunger would go above it’s capacity and the Ham stops itself. It’d be great if there was an option to reinitialize the plungers mid run to recover from this.
Even though the Aspirate and Dispense volumes are the same, the volume of air being pipetted due to Liquid Class settings must be considered as well (namely Blowout Volume on Aspirate vs. Dispense). If all of the liquid and air are not being dispensed, then the plunger position will continue to rise in the channel until it reaches the max.
The reason this error occurs on cLLD, but not pLLD, is due to a difference in plunger activity. When using pLLD, the plunger resets to zero before beginning the liquid approach (this allows maximum travel distance). This positional reset would be “dispensing” the air remaining inside the tip. When using cLLD, the plunger does not reset, so all movement begins from its current position.
Just wanted to add here that I’m also experiencing the same “Slave Command Timeout - Plunger Drive: Position Out of Permitted Area” error message. This error is occurring when using the CO-RE 96 MPH with PhyTip columns on a Vantage running VENUS 6.3. Specifically, this is occurring on the mix steps. I still need to review the method as I didn’t originally write it, so I will update here with relevant information that I find. In the meantime, what are some possible resolutions to this issue? Thank you!
I vaguely remember having issues of the same sort years ago while working with Phytips. In general the dosing plunger can get “confused” sometimes especially when there are a lot of movements that “stack up” in the firmware for the head. Another good example is a large number of retries after an LLD failure. I’ve seen the plunger move slightly each time it goes in for another try. Enough of those will cause this.
One solution I can think of based on this experience is to add an “init dosing drive” (H0DI) step somewhere in the Phytip handling library where it won’t effect your method otherwise. Maybe each time before the tips are picked up and ejected. As I remember there can be a large number of steps and resetting things in this manner could help avoid this.
I’d need to see the Comtrace files to provide a more in depth analysis on the subject.
Hi all,
I’m seeing the same plunger error we’re discussing here when using a core-96 head. What is puzzling is that it only seems to happens at the end of the steps I am working on after seemingly completing the entirety of the step without issue.
The block of steps are as follows:
Aspirate 230ul of lysing reagent from trough using 1000ul 1.2mm widebore filter tips
Dispense into wells containing 230ul of resuspended cells
In the same dispense gold-step, perform 10 mix cycles of 500ul with liquid follow, at a mix flow rate of 30ul/s (very slow to handle the resulting viscous liquid)
Steps ends with the tips being slowly removed at a swap speed of 2mm/s to ensure no sticky strings of liquid remain attached to tips (and works great!)
After the tips are removed and the step ends, I get the hardware error and the script is forced to abort.
I’m investigating possible reasons this error happens, and from the information in this thread I’m wondering if the repeated mix cycling of this viscous liquid is causing the plunger to continually rise until it maxes out.
What are some of the ways to get the plunger reset or at least have the pressure relieved such that I can make it to the next step? Directly following this is a tip eject but it errors just before this is seemingly carried out.
I’m new to this forum so if there is a better way to get the trace file uploaded please let me know. I have pasted the section in question but if more information is required I am happy to provide it.
If you’re on an earlier version, then please submit the run time trace and the COM trace from that day. The COM trace is in the same LogFiles folder as the run trace and would be named: “HxUsbCommYYYMMDD”
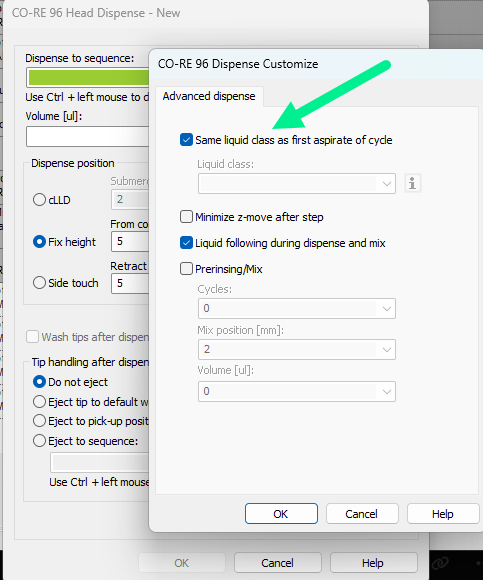
A com trace uploaded as Eric had mentioned would greatly help confirm this, but from what I can see on the snippet you sent, it appears that your dispense is referencing a different liquid class from your aspirate. This could lead to issues like you are experiencing if the air gaps or correction curves do not match each other which puts the dispense drive out of range from where it can reach.
I would recommend checking the box on your dispense step to use the same liquid class for the dispense as the aspirate to correct the issue.
Thank you for the replies. I have the COM trace file from the day I was working on the method and I’ll upload it as instructed by Eric.
The step in question involves aspirating a liquid from a trough, and then dispensing with a mix cycle into wells that contain a cell pellet to resuspend it. During this, the liquid class changes dramatically (becomes very viscous and stringy/sticky), and I thought it made sense to have a second liquid class to heavily slow down the mix flow rate and swap speed during this mix cycle of the dispense step.
Is there a recommended way to utilize two differing liquid classes like this? I could go in and make sure the air gaps and correction curves between the two liquid classes are the same if that is the issue. Whatever suggestions you may have I am very open to. The step works great, I’m able to slowly mix this very viscous solution and have the 96 head rise out slowly without any strings of liquid staying attached to the tip.
Thanks for uploading the COM Trace file. From what I can see, the issue is your MPH is timing out due to the very slow mixing. The STAR has a strict 5-minute timeout from when a command is sent before it throws an error. In your case, with the slow approach/retract, dispense and then 12 cycle mix at 30 uL/s is leading to a total time of > than 5 minutes. When this error occurs the dispense drive will stop at whatever position it left off at in the mix which then leads to the dispense drive out of range error on the repeat attempt.
If the mix speed is working for you, I would recommend lowering the number of mix cycles so that you can stay under the timeout restriction. 7/8 cycles should stay under this limit.
Thank you very much for this information! I was not aware of this 5-minute timeout and will adjust the step to fall below this threshold.
Thank you as well @Pascal for your suggestion. If I am unable to resolve this single dispense/mix step I will definitely try this as an alternative solution.